










ニュース・
新着情報

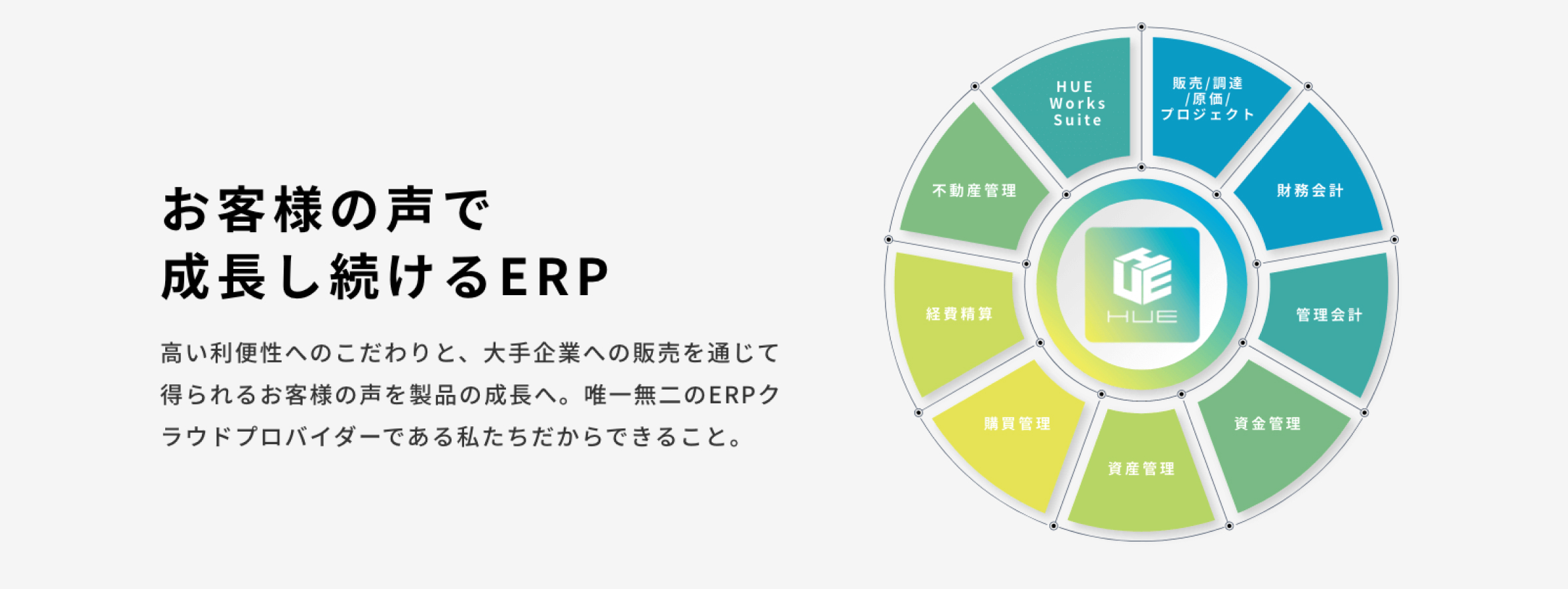
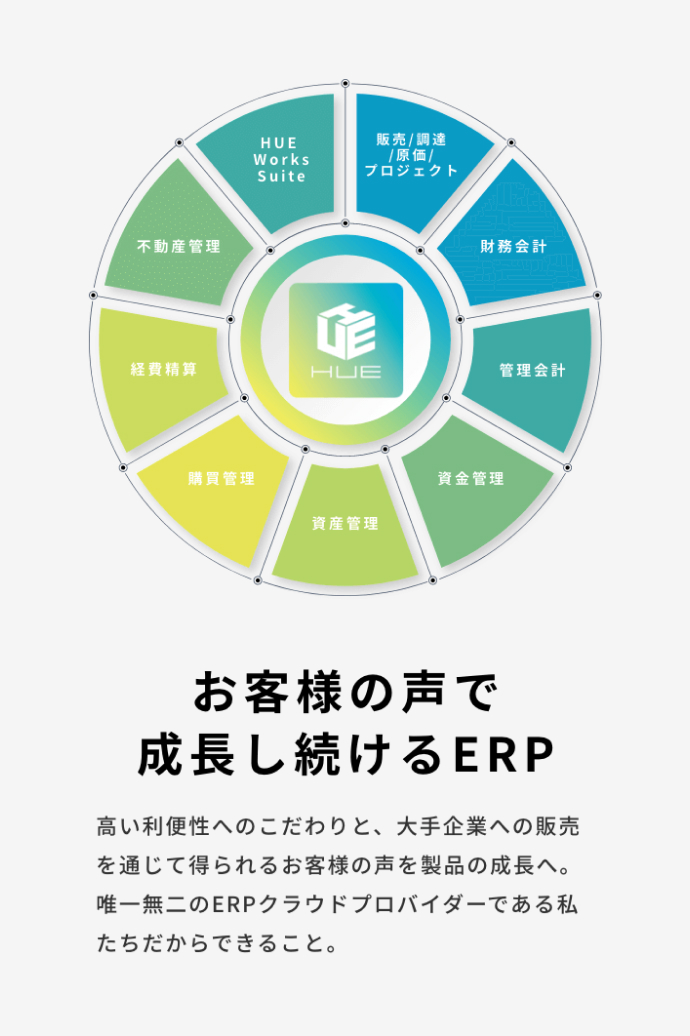
新リース会計基準の適用に向けて、企業が取るべき対応について資料で確認!
2023年5月にASBJより草案が公表された、新リース会計基準への関心が昨今非常に高まっています。
新リース会計基準に関する特設ページでは、新リース会計基準のもとになっているIFRS16号の適用実態適用調査や、影響額を試算するツールのダウンロード、あずさ監査法人による解説セミナー動画をご視聴いただけます。
サービスについて




導入事例
- 製造業
- 卸売・小売
- 建設業
- 教育・学校法人
- 金融・保険
- 情報・通信
- その他







お役立ち情報



その他お問い合わせ・資料請求については
以下お問い合わせフォームもご利用ください。








